하둡이란
하둡
- 빅데이터의 저장과 분석을 위한 분산 컴퓨팅 솔루션
빅데이터
- 한대의 컴퓨터로는 저장하거나 연산하기 어려운 규모의 거대 데이터
- 빅데이터를 다루기 위한 기술 - 하둡
분산 (컴퓨팅)
- 여러대의 컴퓨터로 나눠서 일을 처리함
저장
- 데이터를 저장한다.
- 큰 규모의 데이터(파일)를 어떻게 저장할 것인가
거대한 데이터를 저장하면 알아서 쪼개서 분산되어있는 컴퓨터에 저장을 한다.
파일을 요청하면 그 파일을 다시 붙여서 돌려준다.
파일을 쪼개서 저장할 때 여러개의 컴퓨터에 중복해서 저장한다.
만약에 컴퓨터 하나가 고장나게 되면 유실되지 않도록, 다른 컴퓨터에 중복 저장해서 파일을 쉽고 빠르게 복원할 수 있도록 복원성을 제공하는 것이 하둡의 큰 특징이다.
분석
-
데이터가 저장된 컴퓨터에서 데이터를 분석하고 그 결과를 합친다.
-
여러 대에 쪼개져있는 데이터, 그 데이터를 가지고 있는 컴퓨터들에게 어떠한 연산을 하라고 일괄적으로 명령을 내리면 독립된 컴퓨터들이 자기가 가지고있는 데이터를 분석해서
분석된 결과를 하나로 모아서 만들어주면, 훨씬 더 빠르게 데이터를 처리할 수 있게 된다.
-
이렇게되면 더 많은 컴퓨터가 투입될수록 더 빠르게 데이터를 처리할 수 있게 되는 것이다.
이런 작업에 클라우딩 컴퓨팅을 사용한다.
분석 작업을 위해서 항상 컴퓨터를 유지하는 부담이 없어지는 것이다.
이런 빅데이터는 한대의 컴퓨터로 처리하지 않기 때문에 많은 컴퓨터가 필요한 비용을 해결하기 위한 것이 클라우딩 컴퓨팅이다.
환경 소개
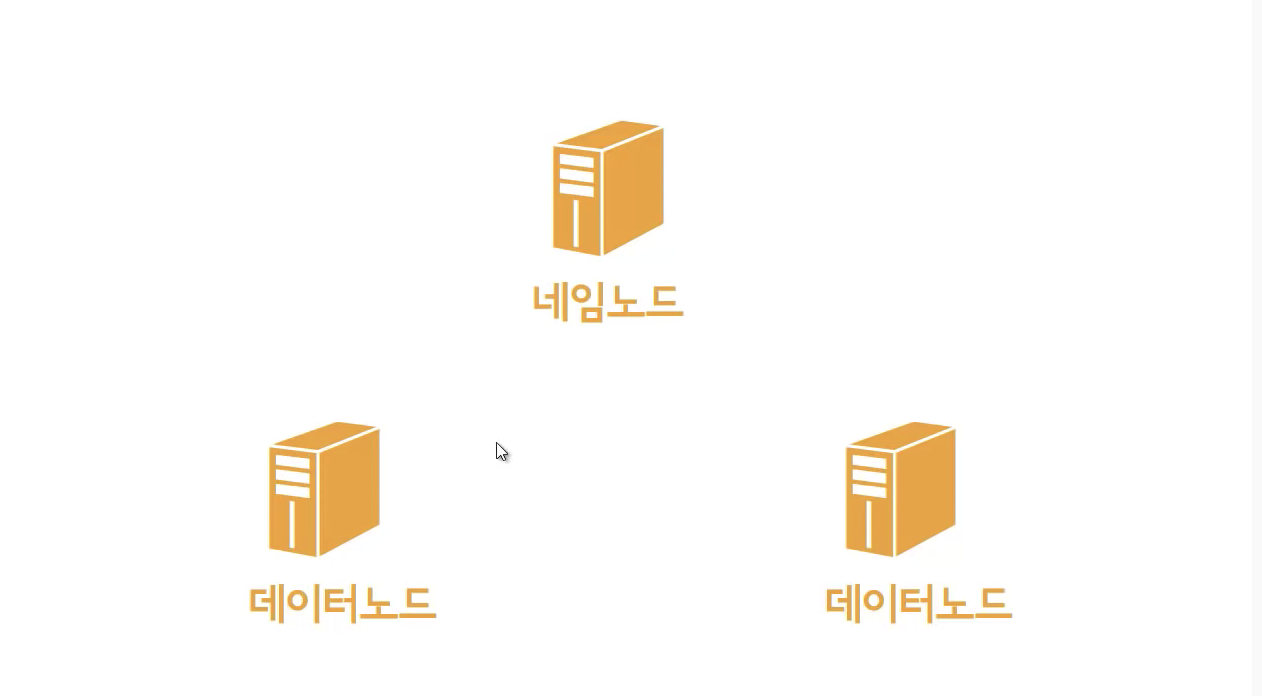
-
네임노드 1대
-
파일을 쪼개주는 역할
-
쪼개진 파일이 어느 데이터 노드에 저장되어 있는가를 기억하고 있다.
이를
메타 데이터라고 한다. -
파일을 저장하면, 파일의 이름, 파일의 조각이 어느 데이터 노드에 저장되어있는가가 네임노드에 저장된다.
-
-
데이터 노드 2대
- 실제로 사용자가 업로드한 데이터를 쪼개진 형태로 보관하고 있는 각각의 컴퓨터
- 환경 소개
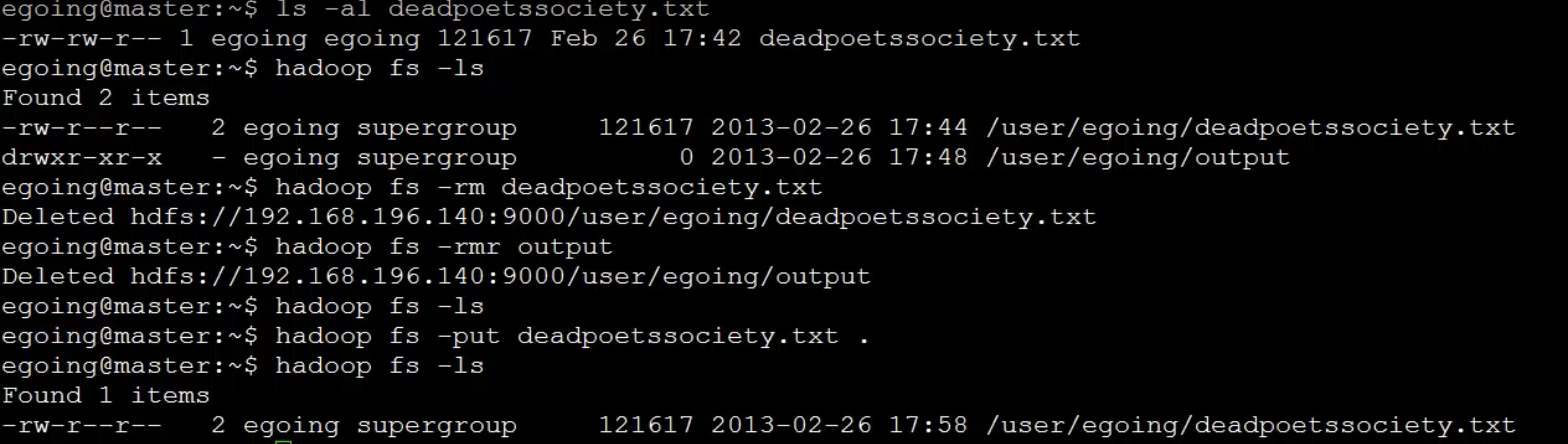
데이터 저장
→ 데이터 노드에 분산돼서 저장된다.
분석
- deadpootssociery.txt 파일에 특정 단어가 몇번 등장하는 가를 하둡시스템을 통해서 계산한다.
- 아주 거대한 데이터 속에서 분석한다고 생각하면 된다.
-
“분산 컴퓨팅 환경에서 쪼개져 있는 데이터를 각각의 컴퓨터가 분석하고, 그 분석한 내용을 합쳐서 하나의 단일 분석 결과를 만들어내는 것” 이 하둡이 하는 일이다.
- 하둡은 빠른 실습을 위해
wordcount라는 모듈을 제공해준다. wordcount는 데이터에서 특정 단어가 몇번 등장했는지를 계산해준다. hadoop-examples-1.0.4.jar파일에 이미 wordcount 자바 프로그램이 패키징되어있는 상태이다.
-
하둡은 자바를 기반으로 만들어졌고, 기본적으로 자바를 사용하는 경우에 가장 좋은 성능이나 편의성을 제공한다.
-
하지만 스트림이라는 기술을 이용하게 되면, 하둡을 꼭 자바를 통해서 제어하는 것이 아니라 php, python, 쉘 스크립트 를 이용해서 하둡을 제어할 수 있다.
-
명령
-
하둡의 파일시스템을 제어 :
hadoop fs -
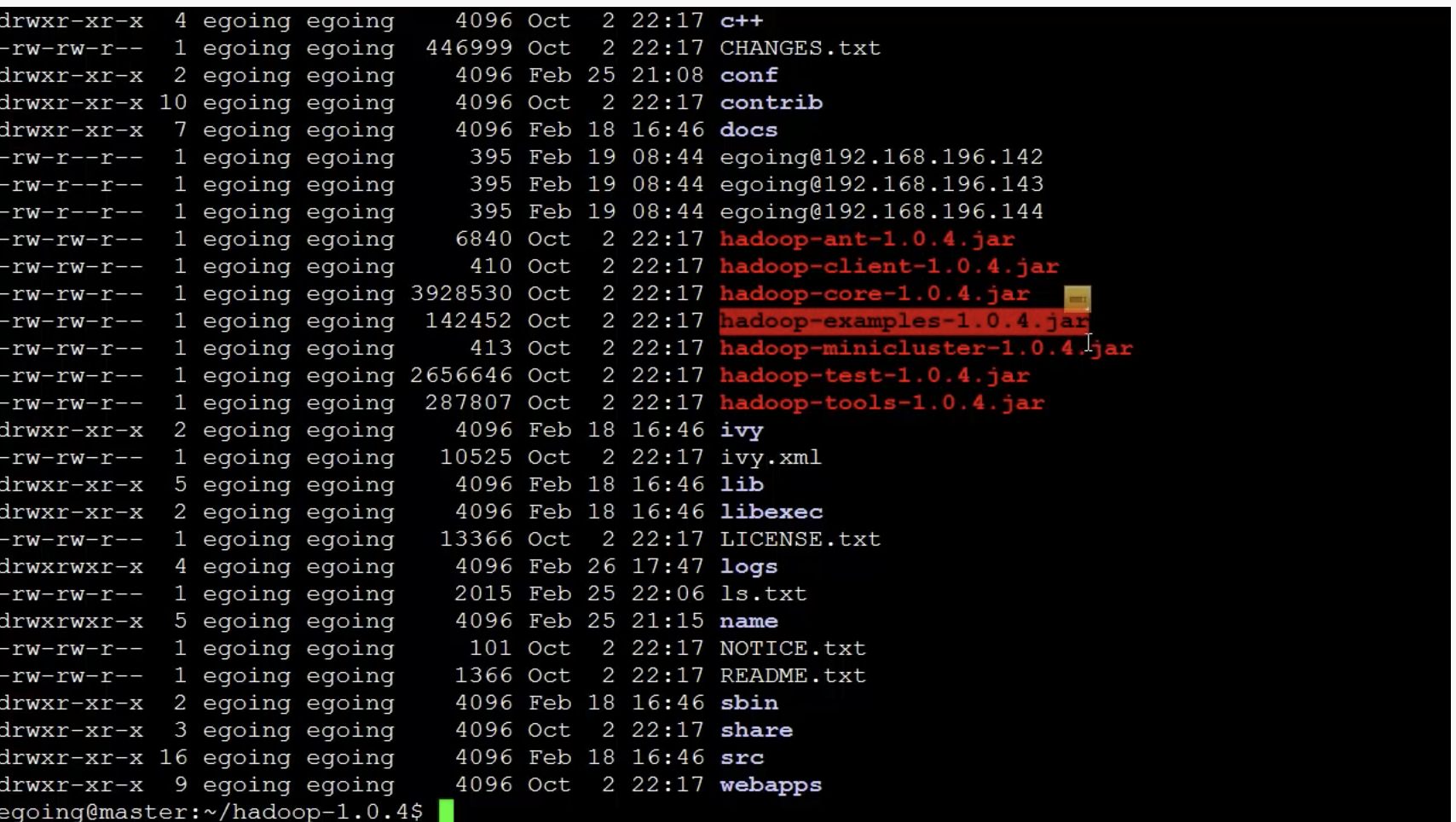
하둡의 MapReduce를 이용해서 데이터를 분석 :
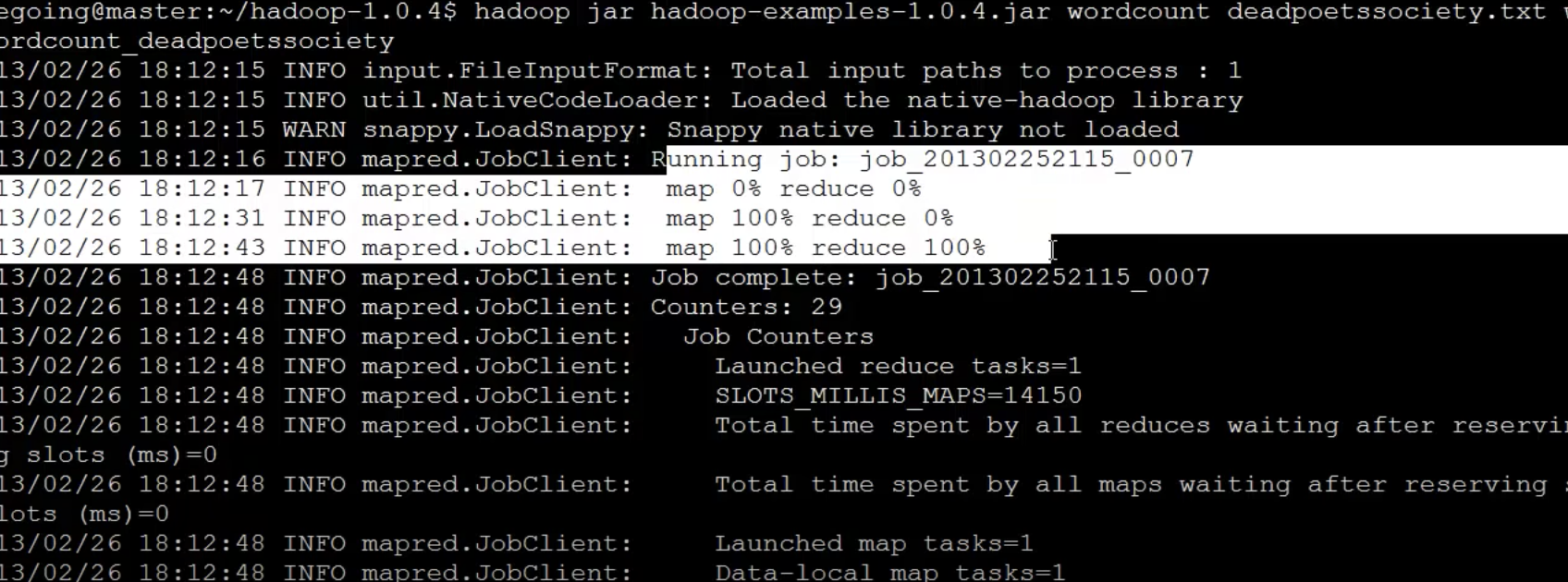
hadoop jar hadoop-examples-1.0.4.jar wordcount deadpootssocierty.txt wordcount_deadpootsssociety- 하둡을 실행할 때,
hadoop-examples-1.0.4.jar파일을 이용해서 분석작업을 하게된다. - wordcount :
hadoop-examples-1.0.4.jar프로그램 중에 wordcount 클래스를 실행시키겠다. - deadpootssociery.txt : 분석할 데이터 (로컬에 저장된 파일이 아니라 하둡 시스템에 업로드한 파일을 지정)
- wordcount_deadpootsssociety : 분석 결과 데이터를 지정할 경로
- 하둡을 실행할 때,
-
-
map과 reduce 작업을 수행
-
하둡은 작은 파일 분석에 최적화된 것이 아니라, 큰파일을 분산하여 병렬로 처리하는데 최적화된 시스템이다.
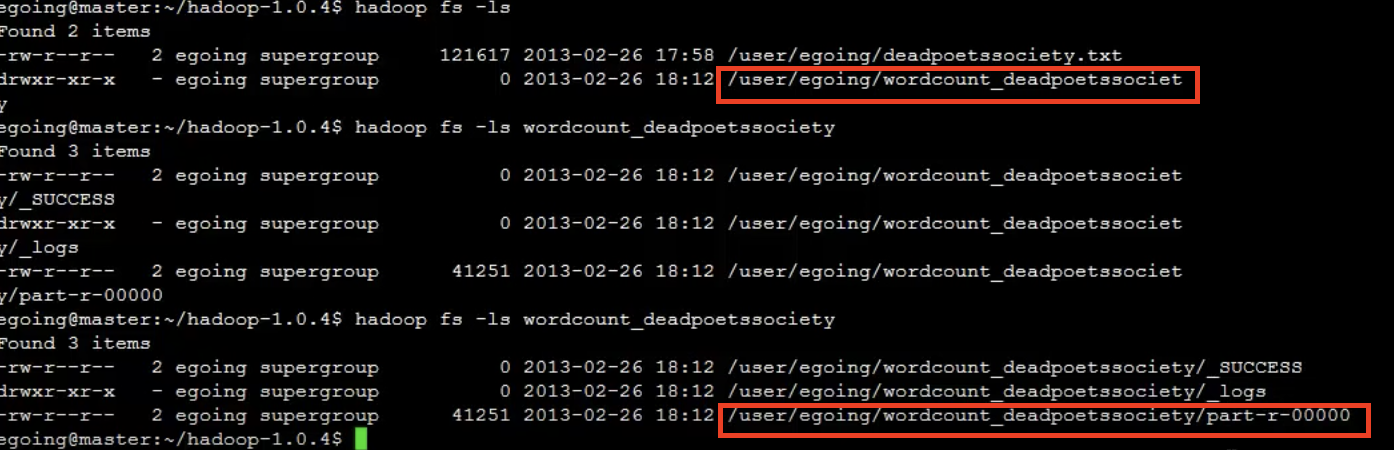
- 하둡 파일시스템의 내용을 조회
- 하둡 명령이 리눅스 명령과 거의 유사하다
hadoop fs -ls
# -> wordcount_deadpootsssociety 디렉토리가 생김
# 그 안에 part-* 로 시작되는 파일에 분석된 데이터 결과가 저장된다.
hadoop fs -cat /usere/egoing/wordcount_deadpootsssociety/part-r-0000
-
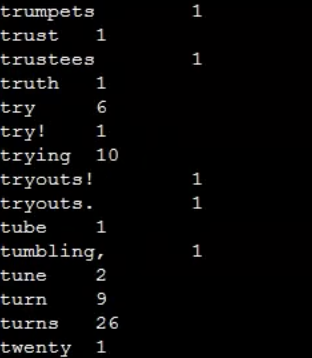
파일 결과
- 각 단어별로 등장횟수