
Spark 10분으로 개념익히기
본문은 YOUTUBE [min zzang]아파치 스파크 개념 설명 강의를 듣고 정리한 내용입니다.
스파크 10분 개념 익히기
스파크란?
-
분석 엔진 툴
-
통합된 분석 엔진을 가지고 분석
-
ETL과 같은 데이터를 이동시키고 데이터를 정제시키는 일련의 작업들을 할 수 있다.
-
특징 1 - “빠르다”
- 스파크는
In-Memory에서 운영된다. 분산 병렬 처리- 클러스터 구조로 운영되어 진다.
하둡도 분산 병렬 처리를 하지만 디스크에서 처리가 되고 스파크는 메모리 위에서 처리되기 때문에 하둡과 비교하여 스파크가 100배 빠르다..!
- 스파크는
-
특징 2 - “사용하기 쉽다.”
- 여러 언어들을 지원해준다. - Java, Scala, Python, R, SQL
Apache Spark Process
- 아파치 스파크에서는 데이터 프레임, 데이터셋, RDD라는 3가지 형태가 있다.
- 그 중, 데이터 프레임을 C컬 언어?로 쉽게 데이터를 정비할 수 있다.
- 리소스 매니저
- Standalone Scheduler, YARN, Mesos
- 스파크는 클러스터 구조로 되어있고, 클러스터 내에 여러 자원들이 논리적으로 나눠져 있는데 이런 자원들을 어떻게 관리할 것인지를 리소스 매니저가 담당한다.
- Standalone Scheduler
- 리소스 매니저를 별도의 프로그램을 설치하지 않고, 스파크 자체적으로 가지고 있다.
- YARN
- 여러대의 서버를 관리해야 하는 경우 YARN(얀)을 많이 쓴다.
- Apache Hadoop Eco System 내에 있는 리소스 매니저로 이 YARN으로 스파크 위에서 리소스 매니저 역할을 한다.
- Mesos
클러스터
- 클러스터란?
- 여러 컴퓨터들의 자원을 가지고 하나의 컴퓨터처럼 사용하는 것
- 보통 Master와 Slave 구조로 되어있다.
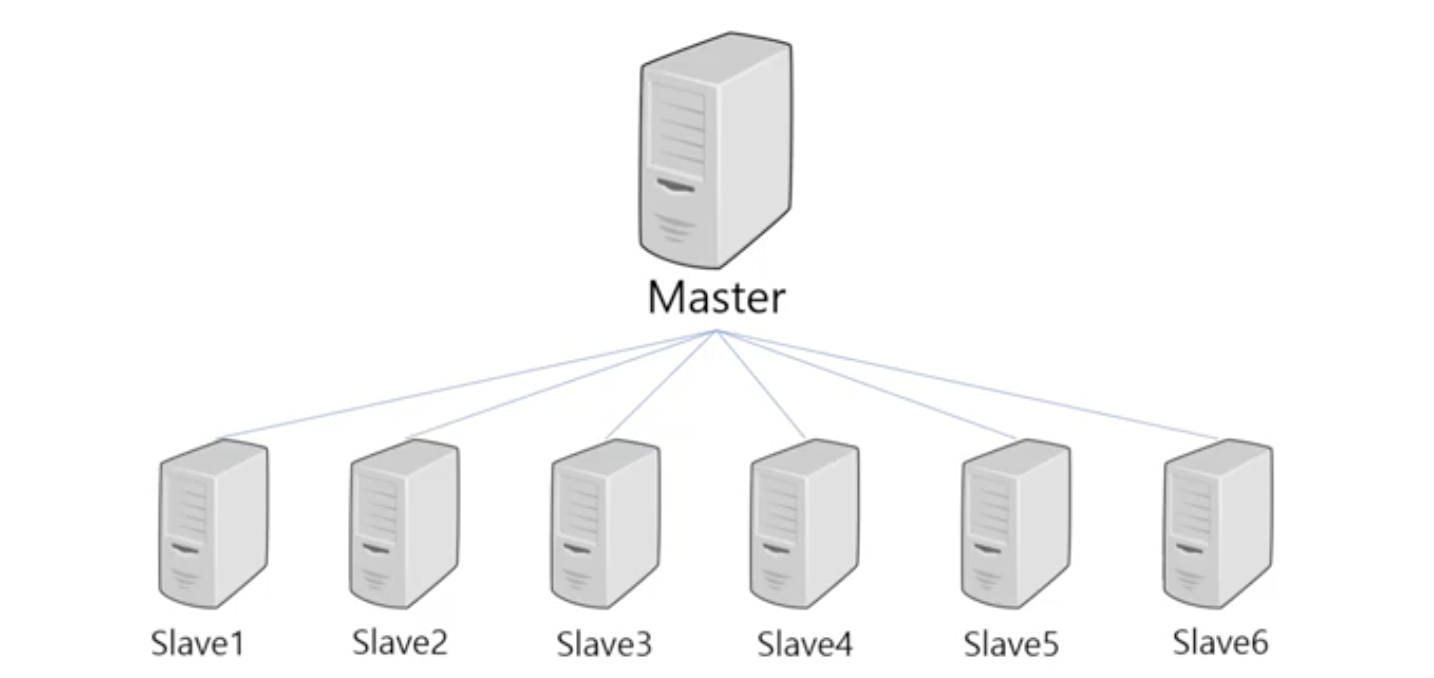
Spark Cluster Infra
- 드라이버 프로세스와 다수의 Worker Node 내의 Executor 프로세스로 구성되어 있다.
- 클러스터는 JVM 위에서 운영된다.
SparkContext
- Driver Program
- 마스터 역할
- Main 함수가 실행된다.
- 스파크 애플리케이션의 정보를 유지 & 관리
- 전반적인 Executor 프로세스 작업에 관련된 스케쥴링 역할
Worker Node
- Slave 역할
Cluster Manager
- 각자 할당받은 리소스(CPU, 메모리)를 관리하는 역할
- 종류 - Standalone Scheduler, YARN, Mesos
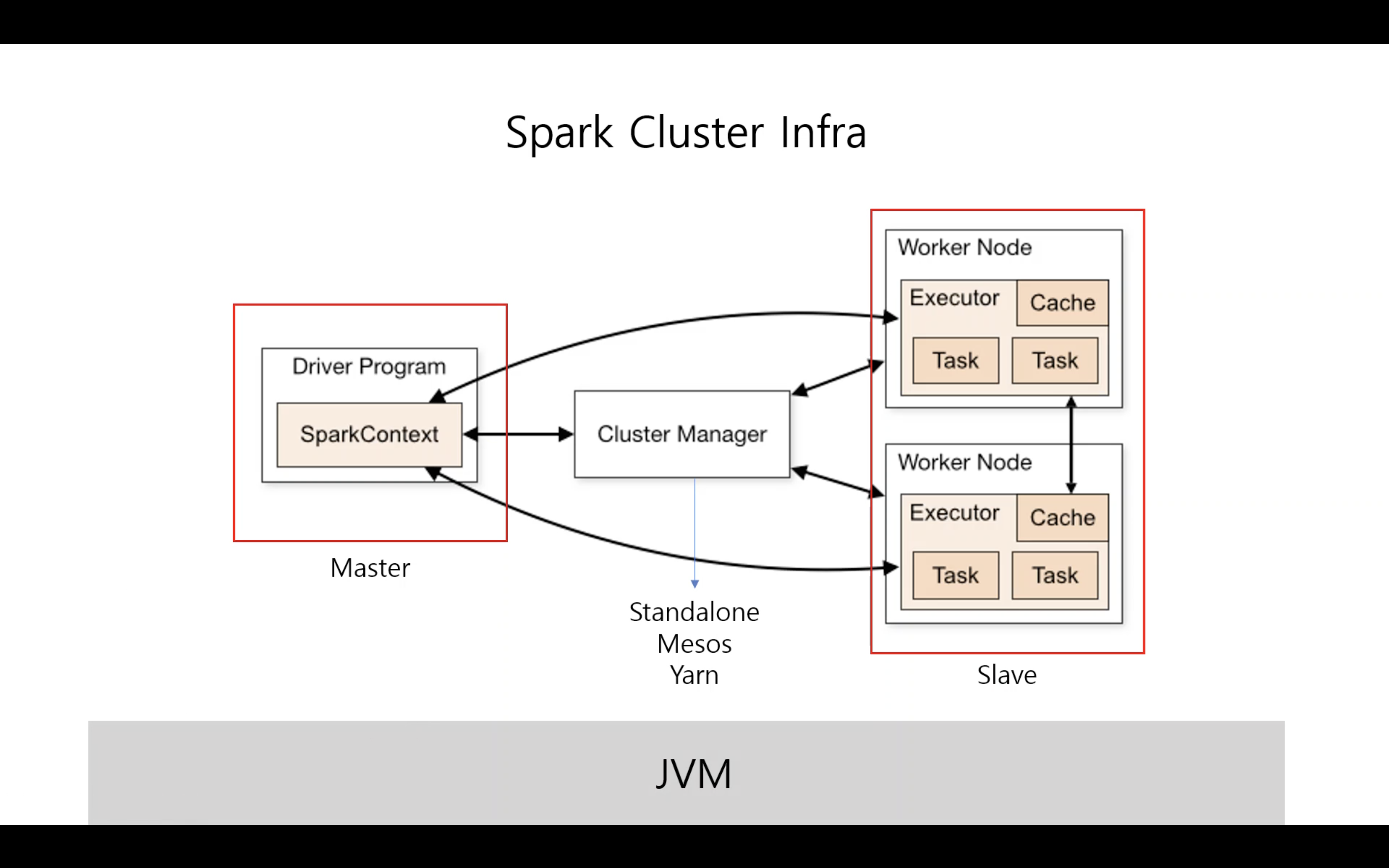
Spark Cluster Standalone
- 한 대의 물리적인 머신 위에 3개의 Thread 프로세스가 실행된다.
- Executor Process 마다 3개의 Core와 메모리를 각자 가지고 있다.
- Standalone Clustermanager라는 리소스 매니저가 Exector 실행을 위해서 리소스를 할당해주는 것이다.
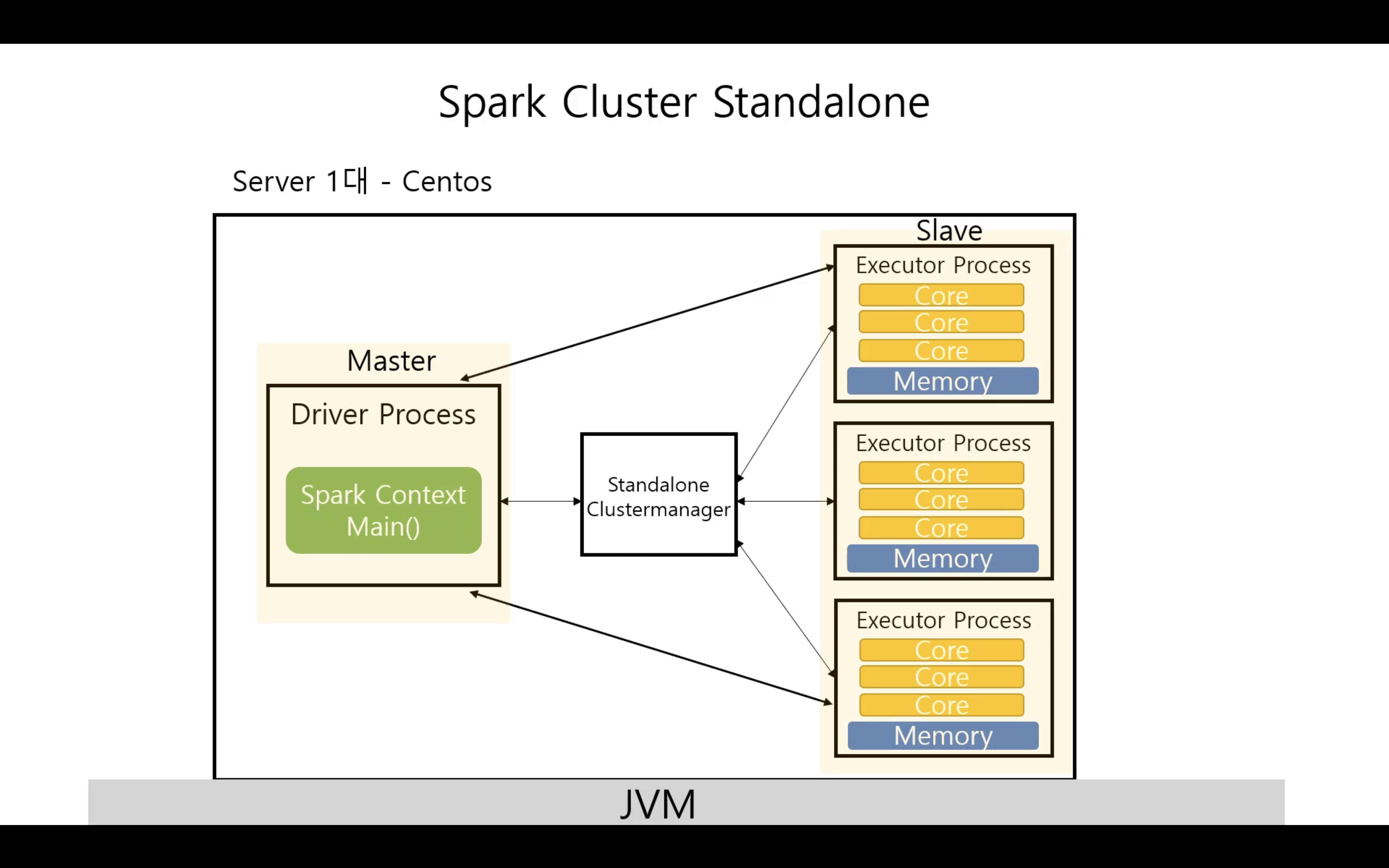
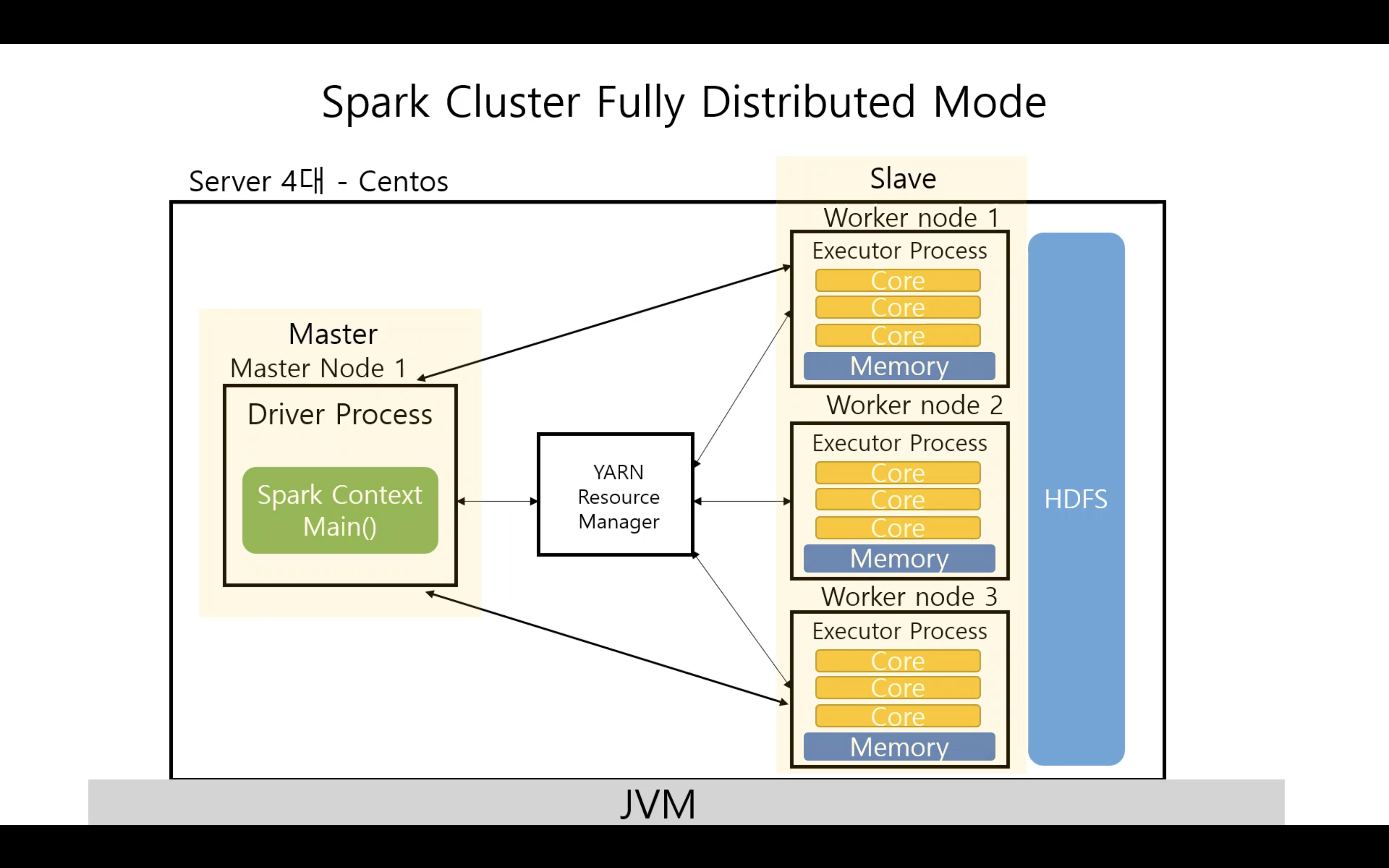
Spark Cluster Fully Distributed Mode (완벽분산모드)
- 물리 장비가 4대
- 마스터 노드에서 1대, 각 Executor Process 마다 한대의 Worker node(서버)에서 실행된다.
- 물리적인 환경만 다를 뿐 클러스터 내 구조는 동일하다.
- YARN Resource Manager가 리소스를 매니징한다.
- YARN은 별도로 설치 및 환경 구성이 필요하다.
- HDFS
- Worker node가 여러대 있는데 결국 공용으로 사용해야할 파일 시스템이 필요하다.
- 이 파일 시스템 또한 분산되어서 저장되고 로드할 때도 분산되어진 데이터들을 한꺼번에 로드시켜서 우리가 사용하는 언어로 애플리케이션을 개발할 수 있는 구조이다.
- HDFS는 하둡 파일시스템이다. YARN을 설치할 때 함께 구성한다.
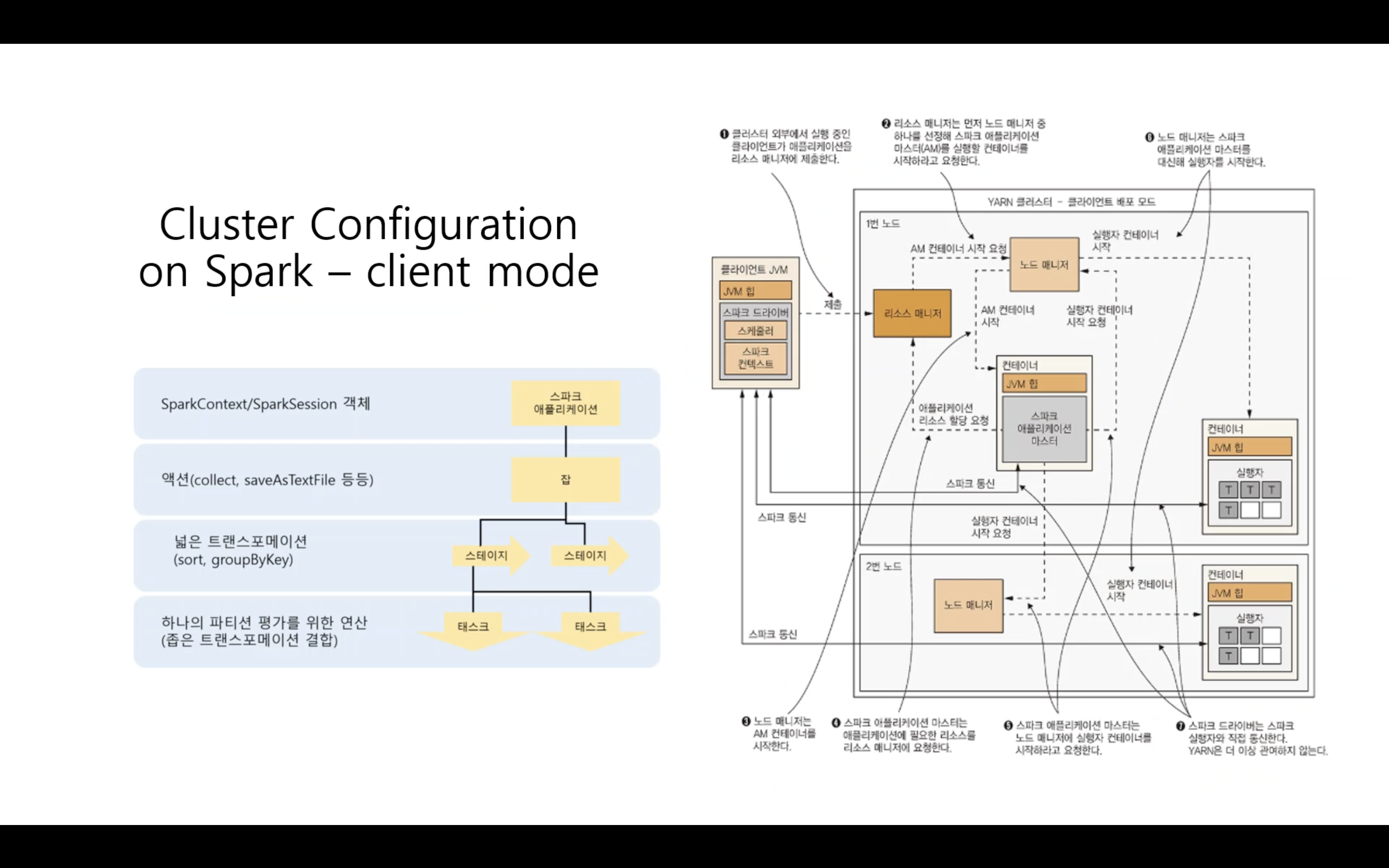
Cluster Configuration on Spark - cluster mode / client mode
- 운영에서의 큰 차이는 없다.
- 스파크 드라이버가 외부에서 실행되느냐, 내부의 마스터에서 실행되느냐의 차이
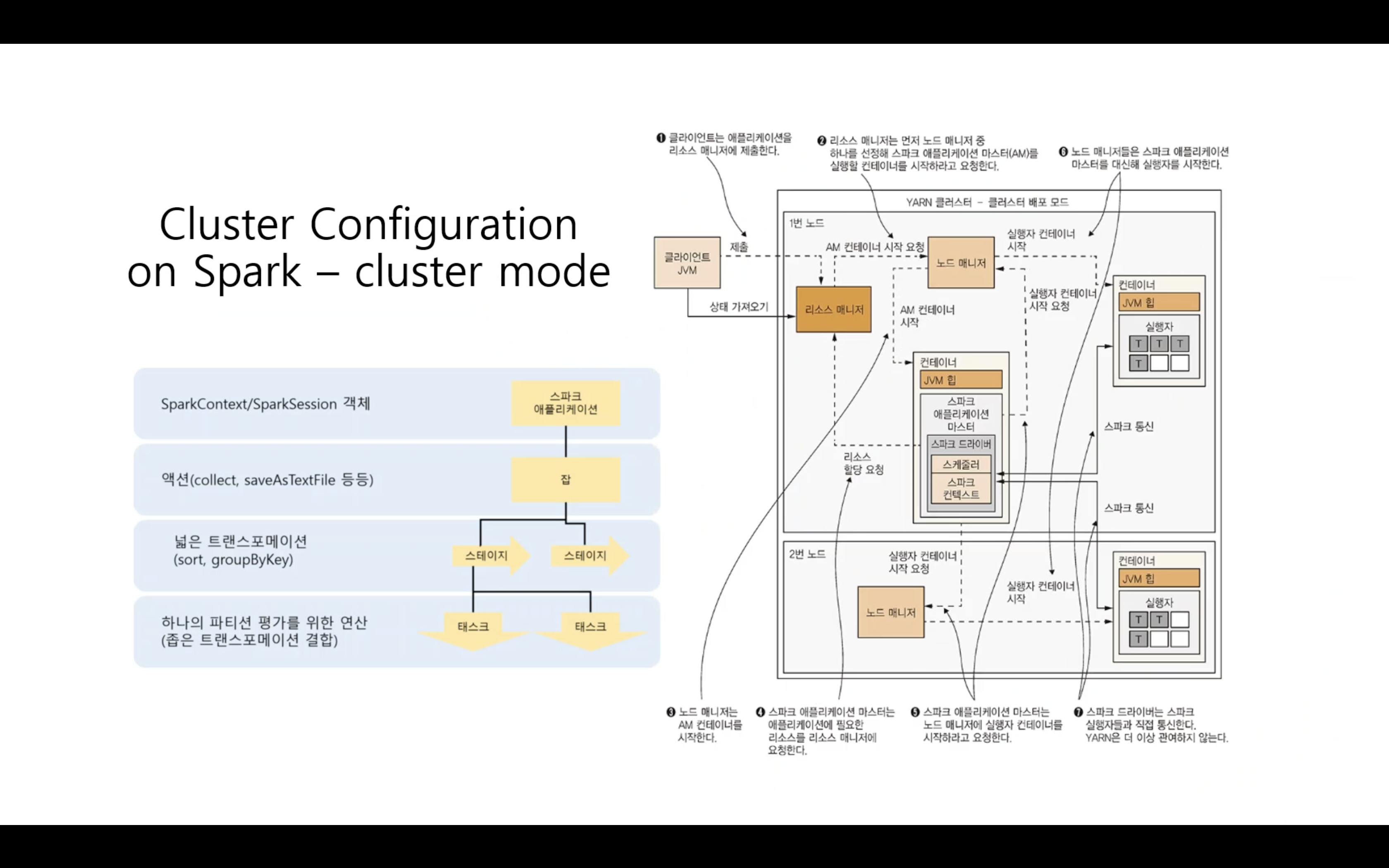
cluster mode
-
스파크 애플리테이션에서 메인 함수가 먼저 실행된다.
→ SparkContext 객체가 생성된다.
-
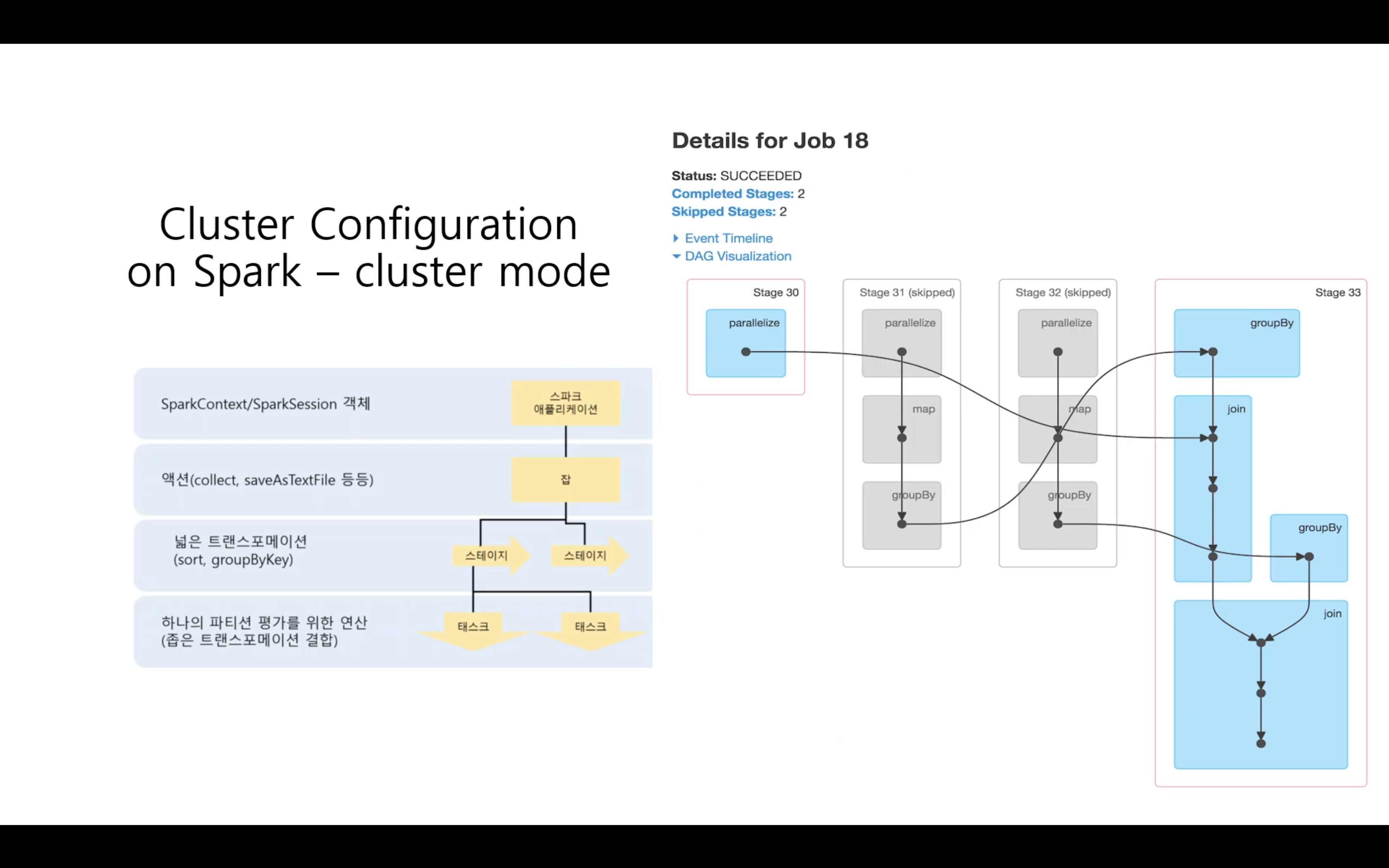
잡
- 스파크는 액션과 관련된 함수를 사용할 때만 코드가 운영되어진다.
- “lazy process”
- 액션과 관련되지 않은 함수를 실행했을 경우에는 실제로 수행하지 않고, “~~한 작업을 해야 한다.”고 기억만 해두고 있다.
- show, count 등의 액션에 도달했을 때까지 실행을 미룬다.
- 액션에 도달하면 잡을 실행한다.
- 액션을 수행하는데 중간에 skipped해도 운영상에 문제가 없어보이는 Stage를 스파크가 알아서 결정을 내려서 운영되어 진다.
-
스테이지
- 잡의 전체적인 계획을 넓게 쪼갠것
-
테스크
- 스테이지 내부에서 진짜로 실행되는 연산
- yarn : hadoop/etc/hadoop
- yarn-site.xml : YARN 리소스 매니저 설정
- hdfs-site.xml : hadoop 파일 시스템 설정
- core-site.xml : 고가용성 파일 시스템이나 보안, 매개변수등을 설정
- mapred-site.xml : 맵리듀스 사이트 설정
- spark : spark
- Spark-env.sh : 스파크에 관련된 환경을 설정. 관련된 패스나 jdk Path 설정
설치해야할 것들
- spark
- java jdk
- hadoop YARN : 리소스 매니저
- Apache Zeppelin : 스파크 위에서 조금 더 편리하게 사용할 수 있게 코드를 좀 더 편리하게 시각화 할 수 있는 툴
- Apach mave, sbt : 스파크 애플리케이션 개발할 때, maven이나 sbt 툴을 이용해서 개발
- Dependency : 기타 여러 의존성들
아니면…
- databricks : 클라우드 환경에서 플랫폼처럼 사용할 수 있다. 따로 구성은 할 필요없이 코드만 넣으면 사용할 수 있게 만들어진 편리한 도구
SparkRDD 개념
Spark API들
스파크에서 제공해주는 다양한 API들이 있다.
API ? - “스파크 애플리케이션 구현 방법”이라고 생각하면 된다.
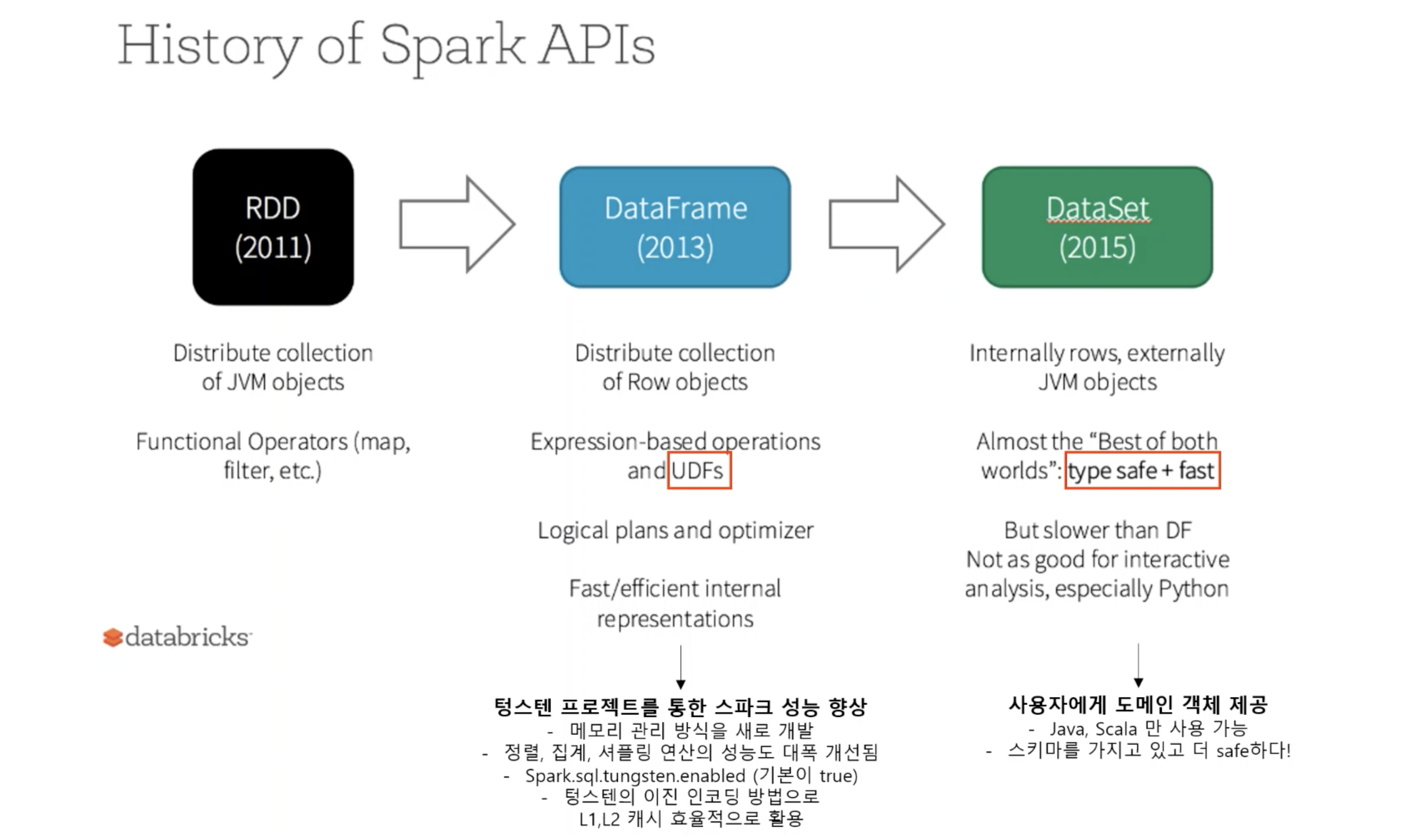
- RDD
- 스파크에서 가장 기본적으로 구현되는 것
- 저수준 API
- 스파크는 DataFrame과 DataSet이 있지만 내부적으로는 RDD 형태로 운영되어지고 있다.
- 여러 서버에서 병렬적으로 처리되는 부분에 있어서 RDD가 그런 목적으로 만들어졌지만 단점이 있다.
- 테이블 조인이나 효율화 처리를 사용자가 직접 제어해야 한다.
- 즉, RDD 로직을 정확하게 이해하고 있는 사용자들이 RDD를 사용했을 때 좋은 효과가 나타나지만 그렇지 않은 경웨는 RDD가 오히려 더 성능 저하를 보일 수 있다.
- 스파크 개발자들이 버전 2부터 DataFrame과 DataSet을 통해서 최적화 엔진을 개발함
- DataFrame
- 고수준 API
- 성능 향상 - 메모리관리 방식을 새로 개발
- 이진 인코딩 방식으로 L1, L2 캐시에 효율적으로 활용되도록 되었다.
- 정렬, 집계, 셔플링 연산의 성능도 대폭 개선됨
- UDF를 사용할 수 있게 되었다.
- UDF : 사용자 정의 함수
- DataSet
- 고수준 API
- type safe + fast
- 사용자에게 도메인 객체 제공
- 데이터를 객체화해서 사용할 수 있게끔 되어있다.
- 스키마를 가지고 있어야하는 API이다.
- Java와 Scala에서만 사용 가능 (Python에서 사용불가)
- (업무에서 많이 쓰임)
RDD
- Resilient Distributed Dataset : 병렬 분산된 데이터셋
- Transformation 연산자와 Action 연산자로 나뉜다.
- Transformation (변환 연산자)
- filter, map
- Action (실행 연산자)
- count, take
이렇게 나눠진 이유 ? - Lazy Evaluation (지연실행)
- Transformation라는 변환 연산자가 있을 경우, 스파크 내부 엔진에서는 아무런 실행이 이루어지지 않는다.
- Action 연산자가 실행되어야할 때, 그때서야 스파크 엔진은 내부적으로 실행이 된다.
- 효율적이고 효과적인 실행결과를 가져온다.
