
컨슈머 Lag(랙)
본문은 인프런의 [데브원영]아파치 카프카 for beginners 강의를 듣고 정리한 내용입니다.
컨슈머 Lag(랙)
카프카 운영에 있어서 아주 중요한 모니터링 지표 중 하나이다.
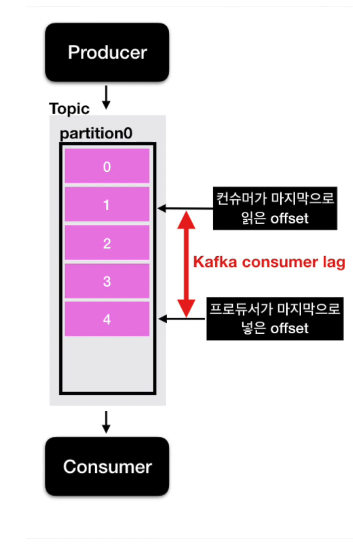
카프카 프로듀서는 토픽의 파티션에 데이터를 넣는다.
파티션에 데이터가 하나하나 들어가게 되면 각 데이터는 오프셋이라는 숫자가 붙게 된다.
- 오프셋 : 파티션에 있는 데이터의 번호
파티션이 1개인 경우, 프로듀서가 데이터를 넣는 상황은 다음과 같다.
프로듀서가 데이터를 넣어주는 속도가 컨슈머가 가져가는 속도보다 빠르게 되면?
**프로듀서가 넣은 데이터의 오프셋**과 **컨슈머가 가져간 데이터의 오프셋** 간의 차이가 발생한다.
이 것이 바로 Consumer Lag이다.
Lag은 많을 수도 적을 수도 있다. 이 Lag의 숫자를 통해 현재 해당 토픽에 대해 파이프라인으로 연계되어있는 프로듀서와 컨슈머의 상태에 대해 유추가 가능하다.
주로 컨슈머의 상태를 확인할 때 사용한다.
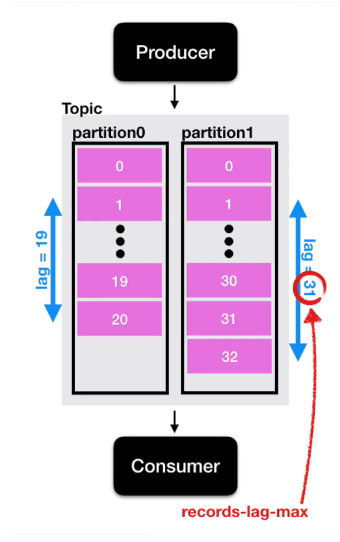
Lag은 각 파티션의 오프셋 기준을 기반으로 한다. 그렇기 때문에 토픽에 여러 파티션이 존재할 경우 Lag은 여러개가 존재할 수 있다.
컨슈머 그룹이 1개 이고, 파티션이 2개인 토픽에서 데이터를 가져간다면 ?
Lag은 2개가 측정될 수 있다.
이렇게 한 개의 토픽과 컨슈머 그룹에 대한 Lag이 여러개 존재할 수 있을 때,
그 중 높은 숫자의 Lag을 records-lag-max 라고 한다.
컨슈머 랙 모니터링 애플리케이션, 카프카 버로우
카프카 lag을 모리터링하기 위해 오픈소스인 Burrow를 사용한다.
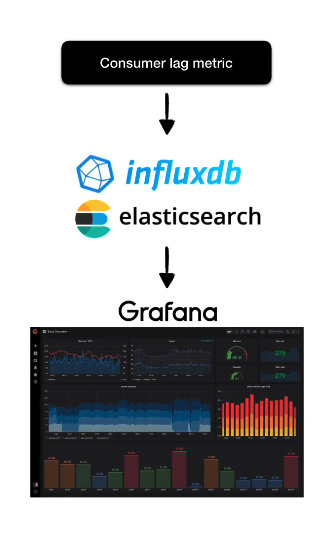
Consumer 단위에서 lag 모니터링
Kafka-client 라이브러리를 사용해서 Java와 같은 언어를 통해 카프카 컨슈머를 구현할 수 있다.
이 때 구현한 KafkaConsumer 객체를 통해 현재 lag 정보를 가져올 수 있다.
lag을 실시간으로 모니터링하고 싶다면 데이터를 Elasticsearch나 InfluxDB와 같은 저장소에 넣은 뒤, Grafana 대쉬보드를 통해 확인할 수도 있다.
Consumer 단위에서 lag을 모니터링 시 단점
-
Consumer 단위에서 lag을 모니터링하는 것은 아주 위험하고 운영요소가 많이 들어간다.
-
컨슈머 로직단에서 lag을 수집하는 것은 컨슈머 상태에 디펜던시가 걸리기 때문이다.
컨슈머가 비정상적으로 종료되면 더이상 컨슈머는 lag정보를 보낼 수 없기 때문에 이후 lag을 측정할 수 없게된다.
- 추가적으로 컨슈머가 개발될 때 마다 해당 컨슈머에 lag정보를 특정 저장소에 저장할 수 있도록 로직을 개발해야 한다.
- 컨슈머 lag을 수집할 수 없는 컨슈머라면 lag을 모니터링 할 수 없으므로 운영이 까다로워진다.
⇒ 링크드인에서 아파치 카프카와 함께 카프카의 컨슈머 lag을 효과적으로 모니터링 할 수 있도록 Burrow를 내놓았다.
Burrow
- Golang으로 작성되었고 오픈소스이다.
- 깃허브에 올라와 있다.
- release 날짜가 최근임 → 지속적으로 관리되고 있는 오픈소스이다.
컨슈머 lag 모니터링을 도와주는 독립적인 애플리케이션이다.
특징
-
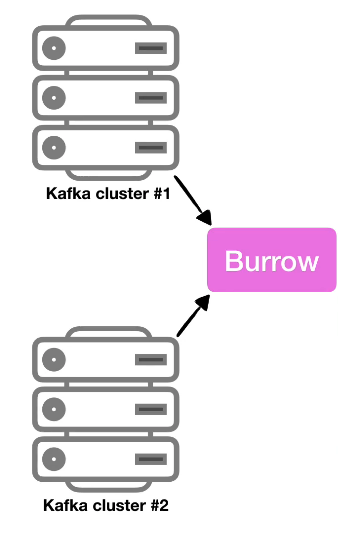
멀티 카프카 클러스터 지원
카프카 클러스터를 운영하는 기업이라면 대부분 2개 이상의 카프카 클러스터를 운영하고 있다.
카프카 클러스터가 여러개더라도 Burrow 애플리케이션 1개만 실행해서 연동한다면,
카프카 클러스터들에 붙은 컨슈머의 lag을 모두 모니터링할 수 있다.
-
Sliding window를 통한 Consumer의 status 확인
Burrow는 Sliding window를 통해서 consumer의 status를
ERROR,WARNING,OK로 표현한다.- WARNING : 데이터의 양이 일시적으로 많아져서 consumer offset이 증가되고 있는 경우
- ERROR : 데이터 양이 많아지고 있는데 consumer가 데이터를 가져가지 않는 경우
-
HTTP API 제공
이와 같은 정보들은 Burrow가 정의한 HTTP API를 조회할 수 있다.
가장 범용적으로 사용되는 HTTP를 제공하기 때문에 다양한 추가 생태계를 구축할 수 있다.
response받은 데이터를 시계열DB와 같은 곳에서 저장하는 application을 만들어서 활용할 수 있다.
Burrow를 통해 수집된 데이터는 추후 애플리케이션 개발과 운영에 많은 도움이 된다.