
카프카 컨슈머
본문은 인프런의 [데브원영]아파치 카프카 for beginners 강의를 듣고 정리한 내용입니다.
카프카 컨슈머 애플리케이션
- 컨슈머가 데이터를 가져가더라고 데이터가 사라지지 않는다.
카프카 컨슈머
- 카프카 컨슈머는 토픽 내부의 파티션에 저장된 데이터를 가져온다.
- 폴링(polling) : 데이터를 가져오는 것
컨슈머의 역할
- Topic의 partition으로 부터 데이터 polling
- 메시지를 가져와서 DB에 저장하거나, 다른 파이프라인으로 데이터를 전달할 수 있다.
- Partition offset 위치 기록(commit)
- offset : 파티션에 있는 데이터의 번호
- Consumer group을 통해 병렬처리
- 파티션 갯수에 따라 컨슈머를 여러개 만들 경우 병렬처리할 수 있다.
컨슈머 라이브러리 사용
-
kafka-clients 라이브러리 추가
- kafka broker와 호환 가능한 버전인지 반드시 확인!

-
컨슈머를 사용하기 위해 자바 프로퍼티 설정
자바 프로퍼티로 기본적인 컨슈머 옵션을 지정할 수 있다.
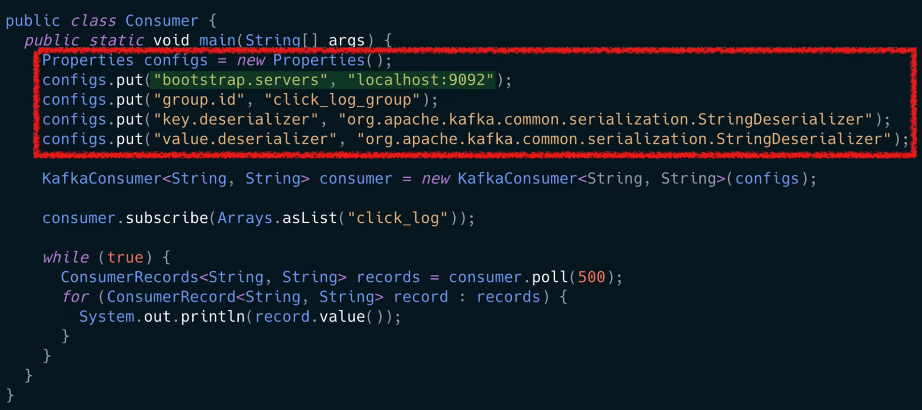
bootstrap.servers옵션 : 카프카 브로커 설정- 카프카 브로커 중 하나의 브로커에 이슈가 생기면 다른 브로커가 붙을 수 있도록 여러개의 브로커를 설정할 것을 추천
group.id: 컨슈머 그룹- 컨슈머들의 묶음
key.deserializer,value.deserializer: key와 value에 대한 직렬화 설정
-
KafkaConsumer클래스를 통해 이전에 선언한 설정들을 매개변수로 하여 consumer 인스턴스 생성-
이 consumer 인스턴스를 통해 데이터를 읽고 처리할 수 있다.
-
consumer.subscribe():컨슈머 그룹을 지정하고 어느topic에서 데이터를 가져올지 지정- 파티션을 지정하지 않으면 모든 파티션에서 데이터를 가져온다.

-
consumer.assign(): 일부 파티션의 데이터만 가져올 수 있다.- key가 존재하는 데이터라면 이 방식을 통해 데이터의 순서를 보장하는 데이터 처리를 할 수 있다.

-
-
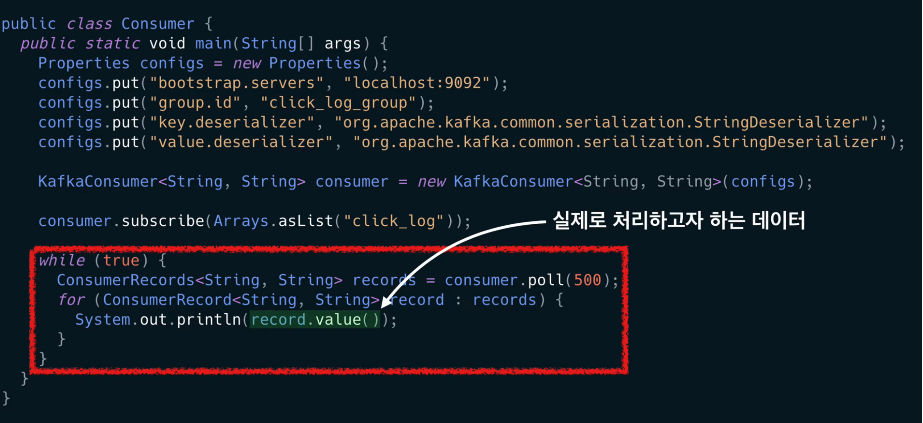
데이터를 실질적으로 가져오는 폴링 루프 구문 작성
-
폴링 루프 : poll() 가 포함된 무한 루프
-
컨슈머 API의 핵심은 브로커로부터 연속적으로 그리고 컨슈머가 허락하는 한 많은 데이터를 읽는 것이다.
- poll() : 데이터를 가져온다.
- poll() 에서 설정한 시간동안 데이터를 기다린다.
- ex) poll(500) : 0.5(500ms)초 동안 데이터가 도착하기를 기다리고 코드를 실행한다.
- 기다린 시간동안 데이터가 들어오지 않는 다면 빈값의 records 변수를 반환
records:데이터 배치로서 레코드의 묶음 list- 실제로 카프카에서 데이터를 처리할 때는 가장 작은 단위인 record로 나누어 처리한다.
records.value(): 실제로 처리하고자 하는 데이터, 이전에 producer가 전송한 데이터
-
데이터가 컨슈머로 전달되는 과정
Producer.send()
프로듀서가 데이터를 넣을 때, key가 null이면 라운드로빈으로 데이터를 넣는다.
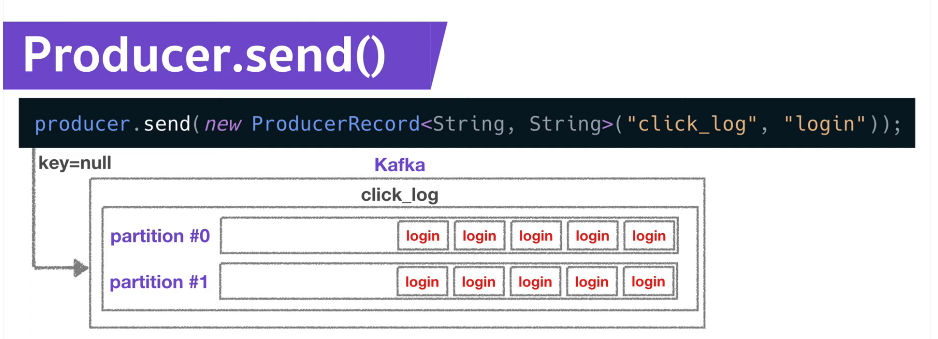
파티션 내에 들어간 데이터는 고유한 번호인 offset값을 갖게 된다.
오프셋은 토픽별, 파티션 별로 별개로 지정된다.
컨슈커가 데이터를 어느 지점까지 읽었는지 확인하는 용도로 사용하게 된다.
컨슈머가 데이터를 읽기 시작하면 offset을 commit하게 된다.
가져간 내용에 대한 정보는 **카프카의 `__consumer_offsets` 토픽**에 offest 정보를 저장한다.
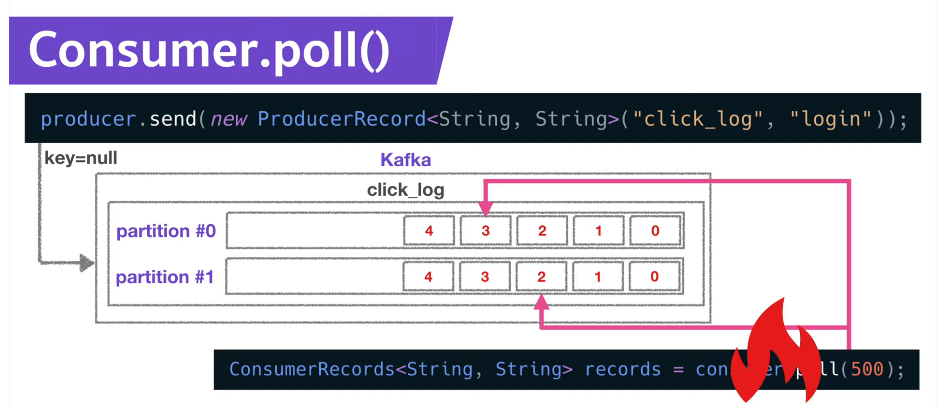
컨슈머는 파티션이 2개인 click_log 토픽에서 데이터를 가져가게 되고, 가져간 정보가 저장된다.
컨슈머가 실행이 중지된 경우, “컨슈머가 파티션 0의 3번 오프셋, 파티션 1의 2번 오프셋까지 읽었다.”라는 정보가 이미 __consumer_offsets에 저장되어있기 때문에 이 컨슈머를 재실행하면 중지되었던 시점을 알고 있으므로 시작위치부터 다시 복구하여 데이터를 처리할 수 있다.
⇒ 컨슈머에 이슈가 발생하더라도 데이터의 처리 시점을 복구할 수 있는 고가용성의 특징을 갖는다.
Multiple Consumer
컨슈머는 몇개까지 생성할 수 있을까?
-
컨슈머 1개
2개의 파티션에서 데이터를 가져간다.
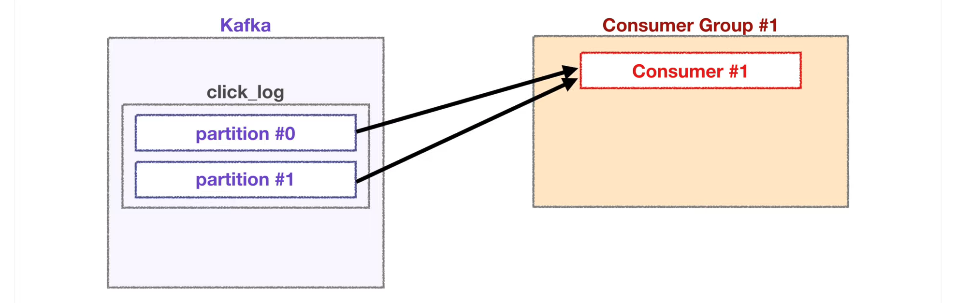
-
컨슈머 2개
각 컨슈머가 각각의 파티션을 할당하여 데이터를 가져가서 처리
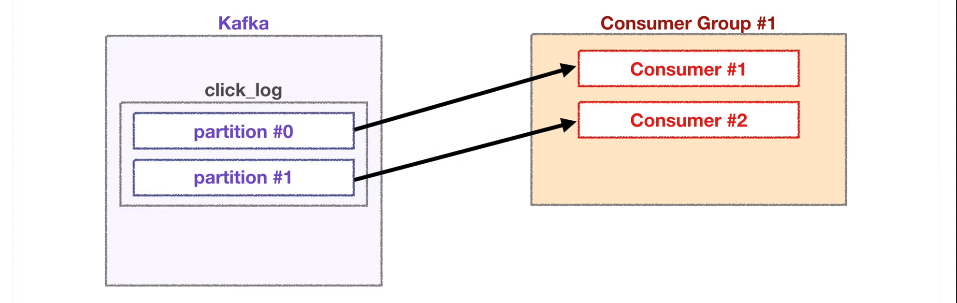
-
컨슈머 3개
이미 파티션들이 각 컨슈머에 할당되었기 때문에 더이상 할당될 파티션이 없어서 동작하지 않는다.
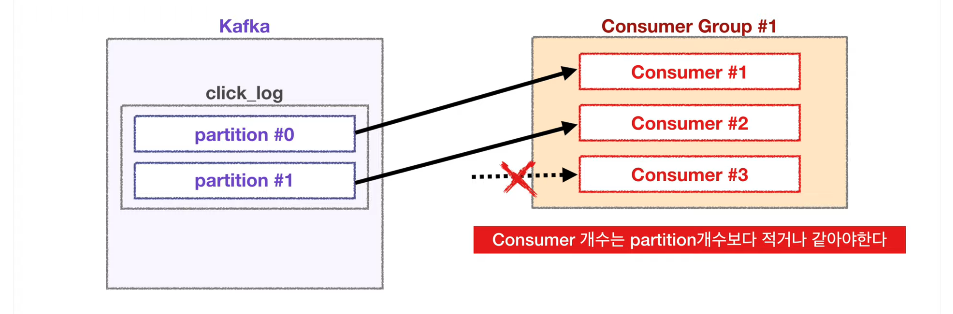
⇒ 여러 파티션을 가진 토픽에서 컨슈머를 병렬처리하고 싶다면,
★ 반드시 컨슈머를 파티션 개수보다 적은 개수로 실행시켜야 한다. ★
Different groups
컨슈머 그룹이 다른 컨슈머들의 동작
- 각기 다른 컨슈머 그룹에 속한 컨슈머들은 다른 컨슈머 그룹에 영향을 미치지 않는다.
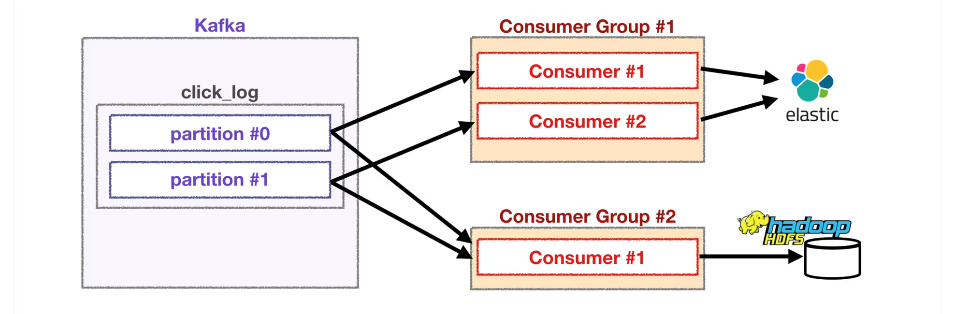
다음과 같은 상황에서 Elasticsearch에 저장하는 컨슈머 그룹이 각 파티션에 특정 offset을 읽고 있어도 hadoop에 저장하는 역할을 하는 컨슈머 그룹이 데이터를 읽는데 영향을 미치지 않는다.
__consumer_offsets 토픽에는 **컨슈머 그룹별**로 토픽별로 offset을 나누어 저장하기 때문이다.
이러한 카프카 특징으로
하나의 토픽으로 들어온 데이터는 다양한 역할을 하는 여러 컨슈머들이 각자 원하는 데이터로 처리될 수 있다.