
TIL - 21.02.07
카프카
링크드인에서 개발되어 2011년 오픈소스로 공개
데이터 처리의 파편화는 유지보수의 어려움으로 직결된다. 이 어려움을 해결하기위해 카프카가 만들어졌다.
카프카는 데이터 처리를 여러 애플리케이션에서 각자 처리하 것이 아니라 중앙에서 처리하는 중앙 집중화 시스템이다. 카프카를 통해 웹사이트, 애플리케이션, 센서 등에서 취합한 데이터 스트림을 한 곳에서 실시간으로 관리가 가능하다.
=> “기업의 대용량 데이터를 수집하고 이를 사용자들이 실시간 스트림으로 소비할 수 있다.”
카프카 특징
- High throughput message capacity
짧은 시간 내에 대량의 데이터를 컨슈머에게 전달할 수 있다. 파티션을 통해 데이터 분산처리가 가능하기 때문에 컨슈머 개수를 늘려서 병렬처리가 가능하다. - Scalability와 Fault tolerant
확장성이 뛰어나다. 이미 사용되고 있는 카프카 브로커가 있더라도 신규 브로커를 추가해서 수평확장이 가능하다. 늘어난 브로커가 죽더라도 이미 replica로 복제된 데이터가 안전하게 보관되어 있으므로 복구하여 처리할 수 있다. - Undeleted log
카프카 토픽에 들어간 데이터는 컨슈머가 데이터를 가져가더라고 데이터가 사라지지 않는다. (다른 플랫폼과의 차이점) 컨슈머의 그룹 아이디만 다르다면 동일한 데이터도 각각 다른 형태로 처리할 수 있다.
Kafka Architecture
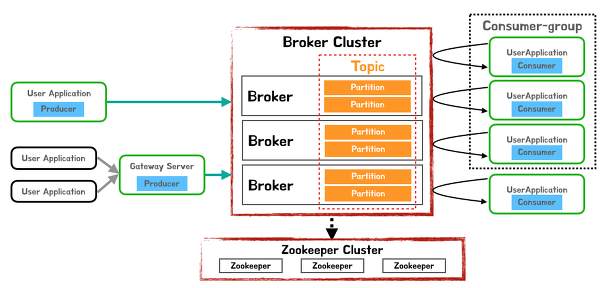
-
Broker : Kafka를 구성하는 각 서버 1대 = 1 broker
- Topic : Data가 저장되는 곳
- Producer : Broker에 data를 write하는 역할
- Consumer : Broker에서 data를 read하는 역할
- Consumer-Group : 메세지 소비자 묶음 단위(n consumers)
- Zookeeper : Kafka를 운용하기 위한 Coordination service(zookeeper 소개)
- Partition : topic이 복사(replicated)되어 나뉘어지는 단위